
Machines Misbehaving
Scientists have found that big tech's algorithms can discriminate, distort, exploit and generally misbehave. Might it be time to create an “FDA for algorithms?”

Cover Photo by James Lee on Unsplash
In the United States, there is currently no federal institution that protects the public from harmful algorithms.
We can buy eggs, get a vaccine, and drive on highways knowing there are systems in place to protect our safety: the USDA checks our eggs for salmonella, the FDA checks vaccines for safety and effectiveness, the NHTSA makes sure highway turns are smooth and gentle for high speeds.
But what about when we run a Google search or look up a product on Amazon? What do we know about the safety of the algorithms behind these systems? While some jurisdictions are pursuing oversight, there is still no “FDA for algorithms,” if you will.
To help show why this is so troubling, I recently conducted a literature review of 62 studies that expose how big tech’s algorithmic systems inflict a range of harms on the public, like predatory ads in a Google search or misleading health products recommended on Amazon. While government institutions have yet to deliver oversight, researchers and journalists have done amazing work to gather empirical evidence of algorithmic harms.
These “algorithm audits” will only become more important as algorithmic systems permeate more of our digital lives.
In this blog post I explain the four main categories of algorithmic harms that I found through the literature review (here is the full preprint, if you prefer):
- Discrimination, like when Amazon’s algorithmic system for screening résumés discriminated against women.
- Distortion, like how Amazon’s search algorithm promotes misinformative health products for vaccine-related search-queries.
- Exploitation, like Google’s ad system exploiting sensitive information about substance abuse for targeted advertising.
- Misjudgment, like when Facebook’s AI erroneously halted ad campaigns for small businesses.
It is no small task to demonstrate how these problems manifest in algorithms. When an algorithm just needs to alphabetically sort a list of contacts, or add up a column in an excel spreadsheet, there is a “correct” answer that makes it easy to check if the algorithm is working.
But the algorithms behind today’s technology often do not have “correct” answers. Think of the algorithm that recommends YouTube videos for you, or the algorithm that suggests which articles you should read on Google News. There are various harms that can surface from these “subjective decision makers” (in the words of Zeynep Tufekci), and there is no single correct answer to check if the algorithm is “correct,” let alone safe and effective. In the studies I reviewed, researchers applied a variety of different “safety checks” to audit public-facing algorithms.
Algorithms that Discriminate
Social problems manifest in algorithms. While more people, including lawmakers like Alexandria Ocasio-Cortez, now recognize how algorithmic systems can exacerbate problems like discrimination, it took a lot of work for that idea to gain traction. A few studies have been particularly important to making this happen.
Early Evidence of Algorithmic Discrimination
Two of the earliest, most formative studies in the literature review focused on discrimination in Google’s search algorithm. In one study published in 2013, Latanya Sweeney tested advertisements that showed up in searches for black-sounding names and white-sounding names. A pattern quickly emerged: criminal report ads showed up in results for black-sounding names (in the paper, a search for “Latanya Sweeney” returned an ad that said “Latanya Sweeney arrested?”)
But in contrast, searches for white-sounding names like “Kristen” did not mention arrest, criminal records, or anything of the sort.
The same year Latanya Sweeney published her report, Safiya Noble published another seminal study about discrimination in Google search. In her excellent book, Algorithms of Oppression, Noble describes the origins of her research in 2010, when she was searching the web for things that would be interesting to her stepdaughter and nieces. Google’s search results were jarring, with five of the top ten results sexualized/pornified.
In the 2013 study, Noble provides a succinct explanation of why discrimination in search results is so impactful:
“Online racial disparities cannot be ignored in search because it is part of the organizing logic within which information communication technologies proliferate, and the Internet is both reproducing social relations and creating new forms of relations based on our engagement with it” (Safiya Noble, 2013)
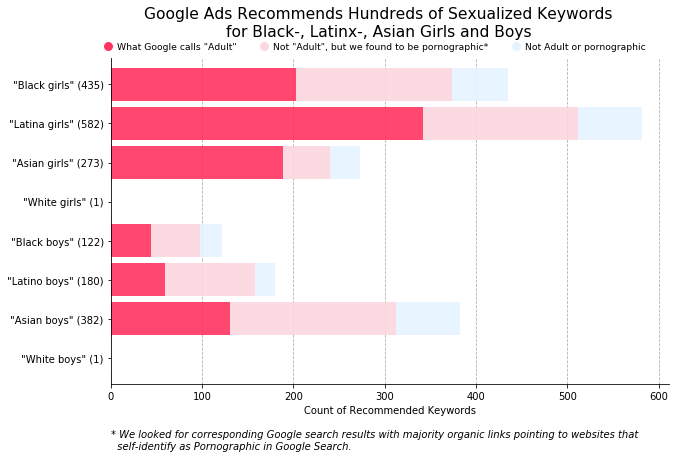
Many technologists think of this kind of issue as a minor “glitch” that can be fixed. But in her book Race After Technology, Ruha Benjamin points out that glitches are neither minor nor easily fixable — they always point to larger systemic issues. Ongoing evidence supports Benjamin: seven years after Noble published her results, The Markup revealed that Google was still making the same egregious mistake on their advertising platform. Here is a chart from their investigation into Google’s “keywords planner” feature:
Computer Vision and Beyond
Another foundational study in algorithmic discrimination was the seminal “Gender Shades” audit by Joy Buolamwini and Timnit Gebru. The study exposed disparities in facial analysis tools made by Microsoft and IBM: light-skinned males were often identified correctly, while darker-skinned females were not. A follow-up study by Buolamwini and Deb Raji found performance disparities in several other commercial systems, but also found that some systems were improving.
In my reading of the literature, these early audits layed the foundation and lit the spark for ongoing work examining algorithmic discrimination. More recently, in an audit published in 2020, researchers Joshua Asplund, Motahhare Eslami, Hari Sundaram, Christian Sandvig, and Karrie Karahalios found that emulating Caucasians led to more housing-related ads while browsing the internet, and emulating African Americans led to more ads for predatory rent-to-own programs.
As employment anxiety grows in the U.S., the public should also be concerned about discrimination in hiring algorithms. In a 2019 study, Maria De-Arteaga and others found significant gender gaps in employment classification systems. Also examining gender discrimination, Sahin Cem Geyik, Stuart Ambler, and Krishnaram Kenthapadi demonstrated a method for improving gender representation on LinkedIn’s talent search system.
All this amazing work is still only scratching the surface: the literature review identified 21 studies that explored discrimination — and there are definitely some that I missed! Check out the full paper and/or the list of discrimination audits if you are interested in learning more.
Algorithms that Distort
Many algorithm audits cite a study suggesting that 39% of undecided voters will shift their voting behavior to the candidate favored in search results. So if 100 undecided voters search for candidate Tonald Drump, and the search results favor Drump, then about 39 of the voters are likely to favor Drump as well. This phenomenon is an example of distortion, which has been another focus of algorithm audit studies that highlight algorithms’ gatekeeping power.
The “search engine manipulation effect” just described (study by Robert Epstein and Ronald E. Robertson) has led many audits to check if search engines have partisan leanings. This is a complicated question that does not have a simple “yes or no” answer, especially because “partisanship” is so difficult to measure. Here are three important studies on the subject:
- A 2018 study by Ronald E. Robertson and others found news items on Google were slightly left-leaning but, but also that “Google’s ranking algorithm shifted the average lean of [Search Engine Results Pages] slightly to the right.”
- A study by Stanford researchers conducted during the 2018 midterms observed “virtually no difference” in the distribution of source partisanship between queries for Democrats versus Republicans.
- Another study by my colleague Daniel Trielli and my advisor Nick Diakopoulos found the “Top Stories” box did have more articles from left-leaning sources, but this reflected an overall trend across the internet (based on a huge database of news called GDELT).
Echo Chambers
Partisan distortion is just one of many different kinds that researchers have been exploring. Distortion is also how I labeled studies focusing on “echo chambers” or “filter bubbles” that allegedly only feed people the content they want to see. As with partisanship, there is limited empirical evidence for the filter bubble phenomenon. Evidence actually suggests that internet users see a greater diversity of sources on algorithmic platforms. Algorithms do personalize your online experience, just not to the extent of creating a bubble.
An early personalization audit by Aniko Hannak and colleagues showed that on average only 11.7% of search results were personalized, with personalization occurring more often for searches like “gadgets” and “places.” A later study by Hannak, Chloe Kliman-Silver, and others showed that most personalization was a result of location. A recent study from my lab found that even if users search with different partisan terms (e.g. “beto orourke pros” versus “lies by beto orourke”), Google has a mainstreaming effect and shows similar, consistent results.
But mainstreaming also means that algorithmic systems can concentrate attention to a small set of sources, as we found in a study of Apple News. This is especially problematic when it leads to source exclusion, for example, a recent audit by Sean Fischer, Kokil Jaidka, and Yphtach Lelkes found that Google often excludes local news from their results. By diverting traffic away from local journalism, Google could be contributing to the crisis in local news and the spreading of “news deserts” across the United States, as studied by Penny Muse Abernathy.
Misinformation
A final kind of distortion relates to low-quality media such as false information, junk news, or other opportunistic content. (The term “fake news” is less helpful nowadays since it was co-opted by politicians, conspirators, and extremists). One audit, led by Rediet Abebe, found that search results for HIV/AIDS can suggest “natural cures” which have been proven ineffective or even harmful.
Researchers have also found misinformation rabbit holes on YouTube, though it appears some like the “chemtrails” rabbit hole have been addressed. In a quick YouTube search, both the search results and the recommendations led to videos with factual explanations:
In total, the literature review included 29 audits that focused on distortion, so again this has just been a sampling. The full list is here, and includes some new additions that are not in the paper because they were not published yet.
Algorithms that Exploit
The refrain that “big tech profits off your data” has become more popular recently, and some audits focused on how this plays out. Most public dialogue focuses on invasive data collection, and indeed, research shows why the public should be disturbed. In one study led by José González Cabañas, researchers found that Facebook’s explanations were misleading, and obscured how Facebook was exploiting sensitive attributes for targeted advertising. Another study led by Amit Datta found a similar case on Google.
A second type of exploitation involves the labor of producing information for algorithmic systems. For example, one study showed that without user-generated content from sites like Wikipedia, Twitter, and StackOverflow, Google’s search engine would not work nearly as well. A follow-up study led by my colleague Nick Vincent found that Wikipedia content, which is created through voluntary labor, appears in 81% of result pages for trending searches, and 90% of result pages for searches about popular controversies like “Death Penalty” or “Israeli-Palestinian Conflict.” The study also found that Google heavily relies on news media for search results, even though Google still does not meaningfully pay publishers.
This exploitation is the foundational concept for thinking of data as labor and considering ways that platforms could compensate the labor that fuels their algorithmic systems. For example, using the profit from people’s data, a platform could fund public goods like parks, WiFi, and infrastructure, or simply write every user a check, as the Brave browser does.
Algorithms that Misjudge
Misjudgement is different from the other types of behaviors, serving as kind of a broad meta-category. In the literature review, I recommend that future audits try to focus on a more specific problematic behavior to make the risks and harms of algorithms as clear as possible. Still, there were some interesting studies of general “misjudgment” worth mentioning here.
One important kind of misjudgment happens fairly often in advertising platforms, which you may be familiar with if you have ever wondered, why on earth am I seeing this ad? As it turns out, algorithmic systems often infer false interests or false demographic attributes for targeted advertising. A 2019 study, led by Giridhari Venkatadri, found that about 40% of targeting attributes on platforms like Epsilon and Experian were “not at all accurate.” As a clear example, some users inferred to be corporate executives were actually unemployed.
These errors could be interpreted as evidence of a potential “digital advertising bubble,” recently described by author Tim Hwang as “the subprime attention crisis.” In short (no pun intended), advertisers probably would not pay as much for targeted advertising if they knew that 40% of targeting features were “not at all accurate.”
Conclusion
New technology always comes with new risks to the public, and through this literature review I found 62 studies (and counting) that highlight risks of the algorithms that power Google, Amazon, Facebook, and other big tech platforms. From discrimination, to distortion, to exploitation, to misjudgment, researchers have shown that algorithmic systems can and do harm the public, not just in sci-fi plots or ivory tower hypotheticals, but in our real world.
That’s the bad news.
The good news is, in the words of Arundhati Roy, “another world is not only possible, she is on her way.” We can turn the ship around by working together as a coalition of users, researchers, journalists, and other stakeholders. We can design, build, and use systems that serve the public interest, rather than just corporate interest.
There is much work to do, and many obstacles in the way, but together we can forge better relationships with our technology.